Should You Let AI Read Your Site for Free?
The advice making the rounds in marketing circles right now is short and satisfying. The AI bots are freeloaders, they take your content and send nothing back, so block them. One click in Cloudflare and you're done.
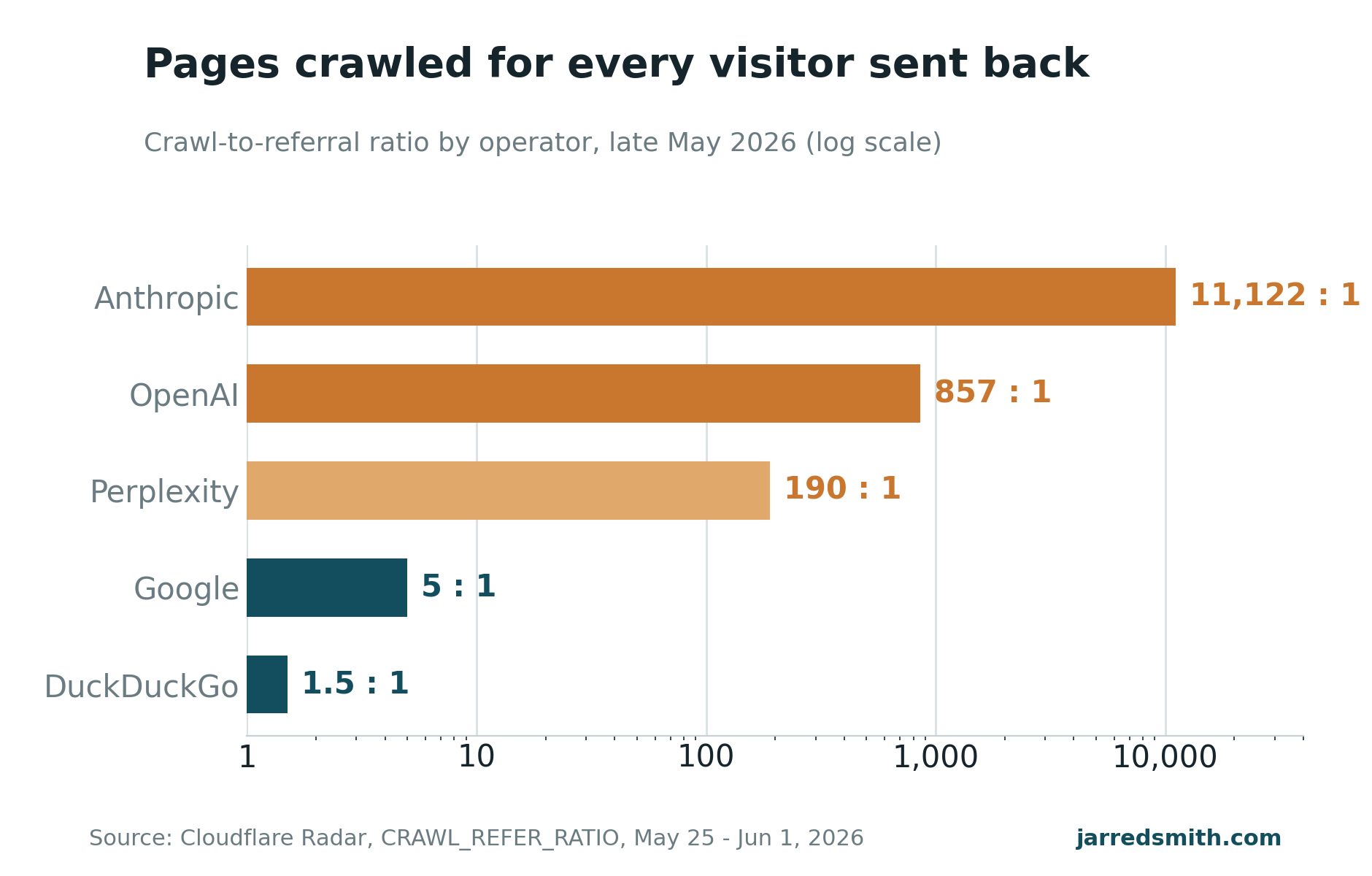
I understand the appeal, and the numbers behind it are real. In the week of May 25 to June 1, Cloudflare clocked Anthropic's ClaudeBot crawling 11,122 pages for every single visitor Anthropic sent back to the web. OpenAI's ratio was 857 to one. Google's traditional crawler, by comparison, runs about 5 to one, because Google Search exists to send you traffic and always has (Cloudflare Radar, via TechnologyChecker). When you're looking at a number like 11,000 to one, blocking starts to feel like plain self-defense.
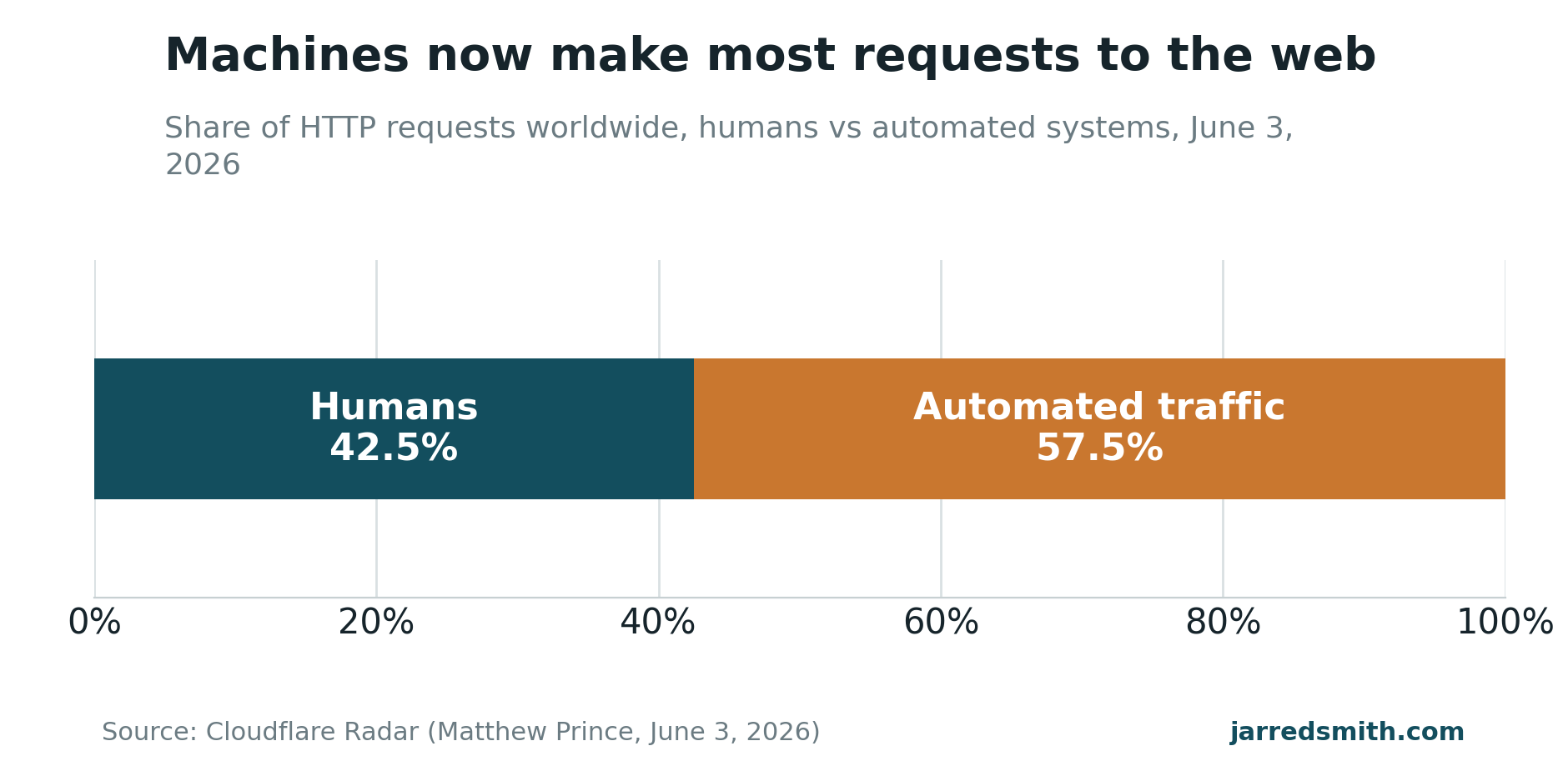
The backdrop got stranger this month too. On June 3, Cloudflare's Matthew Prince reported that automated traffic had crossed 57.5 percent of all requests to the web, the first time machines have outnumbered people, and conceded it showed up more than a year sooner than he'd told a SXSW crowd to expect (TechTimes). The open web ran for two decades on an exchange most of us never thought about: search engines crawl your pages, and in return they send you readers. That exchange is the thing coming apart.
The block reflex is understandable. It's also, for most brands, the wrong default, and the reason is the one I keep writing about. Blocking an AI crawler saves you bandwidth and, in the same move, opts you out of the answer that crawler feeds. For a brand that depends on showing up in ChatGPT, Perplexity, and Google's AI answers, that's a real cost, and it never appears on the bandwidth bill.
The way I'd think about it now has three doors, and which one fits a given bot depends on what that bot is there to do.
Three doors, and why the bot's job decides which one
The three options are block, allow, and charge. Blocking and allowing have been the choices for years; charging is the recent addition, and I'll come to it. The part that makes the whole decision easier is realizing that "AI crawler" covers several jobs that don't behave alike.
Cloudflare classifies what each crawl is for, and the May 2026 split is the most useful number in this whole conversation. About 51.8 percent of AI crawler requests were for training, another 35.7 percent were mixed-purpose, and only 9.3 percent were live search retrieval, with 2.6 percent coming from agents acting on a user's request (Digital Applied's data reference). Roughly seven of every eight AI crawls are feeding a model, not answering a question someone asked this minute. A model trained on your page might surface your name in six months, or never, and you have no way to tell which.
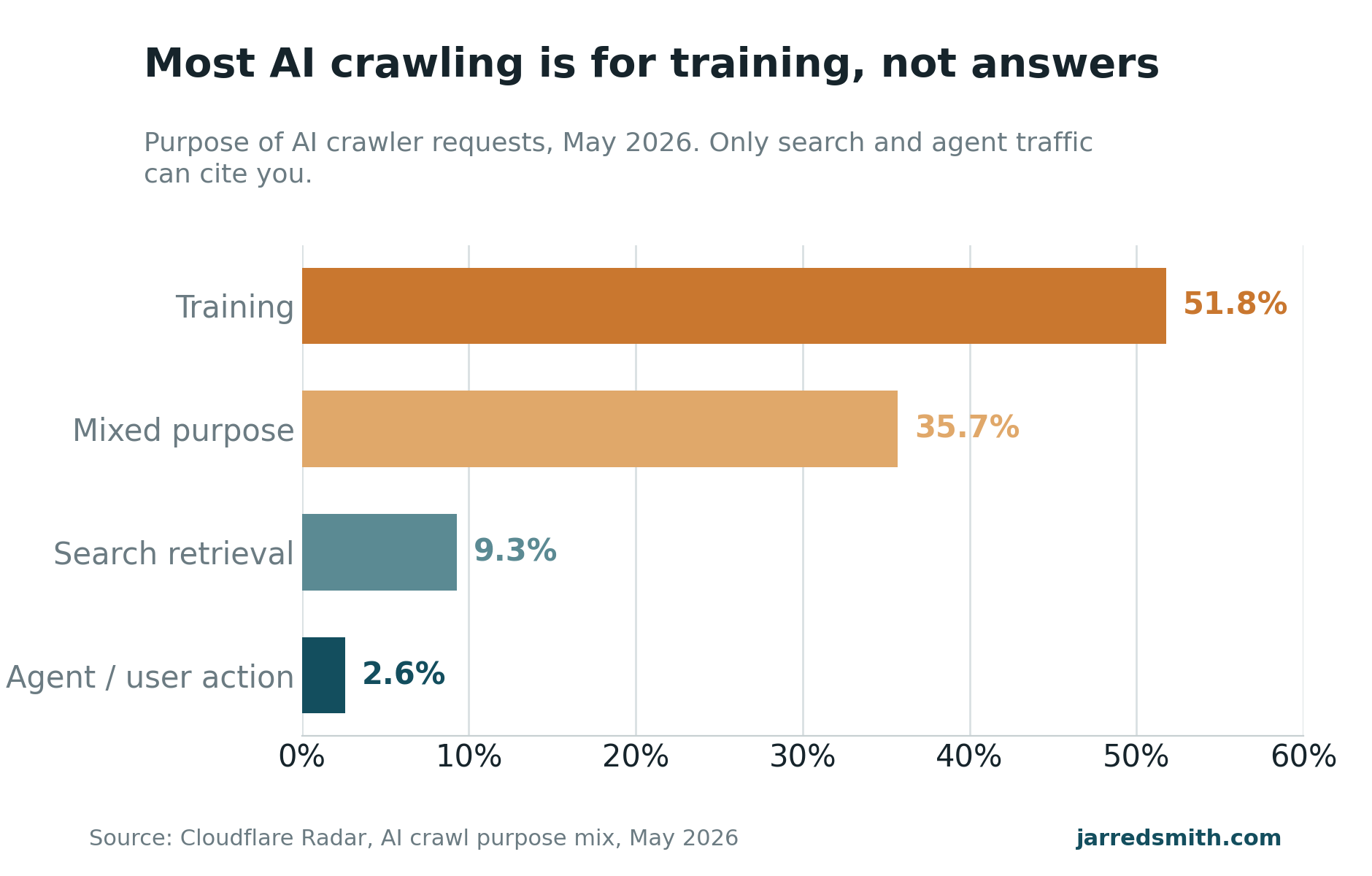
That roughly one-eighth that's search and agent traffic is the slice that can put you in an answer this week. Which gives you the triage.
The training-only crawlers behind no consumer product that sends traffic, things like CCBot and ByteDance's Bytespider, are the freeloaders the block advice is aimed at. If bandwidth or content protection worries you, block or charge them and lose almost nothing in return. The search and user-action bots are a different call. OpenAI's OAI-SearchBot, ChatGPT-User, PerplexityBot, Anthropic's newer Claude-SearchBot, and Google's crawler are how your brand ends up cited and how the occasional high-intent visitor finds you. Those, you keep.
This is roughly where site owners have landed on their own. Cloudflare's analysis of robots.txt files across its network found GPTBot's "allow" share has climbed above its "block" share for the first time, and the welcomed search and user-action bots keep gaining ground. The posture they call "block training, allow search" has gone from a recommendation to the visible consensus (TechnologyChecker's robots.txt report).
Blocking only works if the bot is honest
One caveat sits under all of this. A line in robots.txt is a request, and the well-behaved crawlers honor it. The rest read it as a suggestion. Perplexity got caught last year fetching pages from publishers like Wired that had told it to stay out (Nieman Lab), and Anthropic still lags on the verification standard that lets your server confirm a crawler is who it claims to be, which makes ClaudeBot easy to spoof (Cloudflare). Some of the "ClaudeBot" hits in your logs may be impostors wearing the name and ignoring your rules.
The practical version is that a robots.txt rule is the note you tape to the door. The lock lives at the network or CDN level, so if you mean to block, block there.
Why Google is the one you can't cleanly block
There's a trap waiting for anyone who decides to get tough on AI crawlers, and it has Google's name on it.
Googlebot is the single largest AI-categorized crawler on Cloudflare's network, around 27 percent of AI-adjacent bot requests, and that's because Google runs one crawler to feed two mouths. The same fetch that powers Google Search also feeds Gemini's training. You can't tell Googlebot to stop training the AI without telling it to stop indexing you for search. Cloudflare's read is that this combined design hands Google something like three to five times more web access than OpenAI, Microsoft, or Anthropic, for the plain reason that nobody is going to surrender their Google search visibility to keep Gemini out (Digital Applied). Google has added an AI-output opt-out inside Search Console's settings, which helps at the margin, though the structural fact stands. The crawler with the most extractive potential is the one you're least able to refuse.
Charging is a real third option now
For a long stretch the only people who could charge an AI company for content were the ones with a name big enough to get a meeting. That changed.
Cloudflare made blocking the default for every new domain last July, an event it branded Content Independence Day, and says more than a million customers have since switched on the AI block (Nieman Lab). The newer development is the third door. Pay Per Crawl puts HTTP 402, a "Payment Required" status code that sat unused for about thirty years, to work letting a site charge a crawler per request, with Cloudflare acting as the merchant of record (Cloudflare). The underlying AI Crawl Control tool is generally available now, and Cloudflare customers are firing off more than a billion of those 402 responses on an average day (Cloudflare). Stack Overflow co-launched a paid-crawl setup on the same plumbing (Stack Overflow), and Cloudflare went and bought Human Native, an AI-data marketplace, to run the licensing side, which Prince frames as the company's fourth act (TechBuzz).
If you sit on archives an AI lab genuinely wants, charging is a revenue line that didn't exist eighteen months ago, and it's worth a serious look. For most brands the read is different. Your blog isn't a dataset anyone will write a check for, and the return you should care about is whether the bot that read you puts your name in the answer it gives someone. That sends us back to the door that matters most for you.
How I'd set it up
I'm wary of one-size advice, so treat this as the order I'd work through it, not a checklist to run on autopilot.
Pull your server logs or your Cloudflare bot analytics first and look at who's crawling you and how hard. Most people have never checked, and the volume tends to surprise them. Then allow the search and user-action bots without overthinking it, because those are the path to being cited. Make a real decision on the training-only crawlers based on your own priorities. Leave them in if you treat model inclusion as free brand presence, a bet that being in the training data helps your recall down the line. Block or charge them if you'd rather not subsidize a crawler that returns nothing. Both calls are defensible, which is the part the one-click version skips.
Whatever you do, don't block Googlebot to spite Gemini. You'll lose search traffic to make a point nobody will notice.
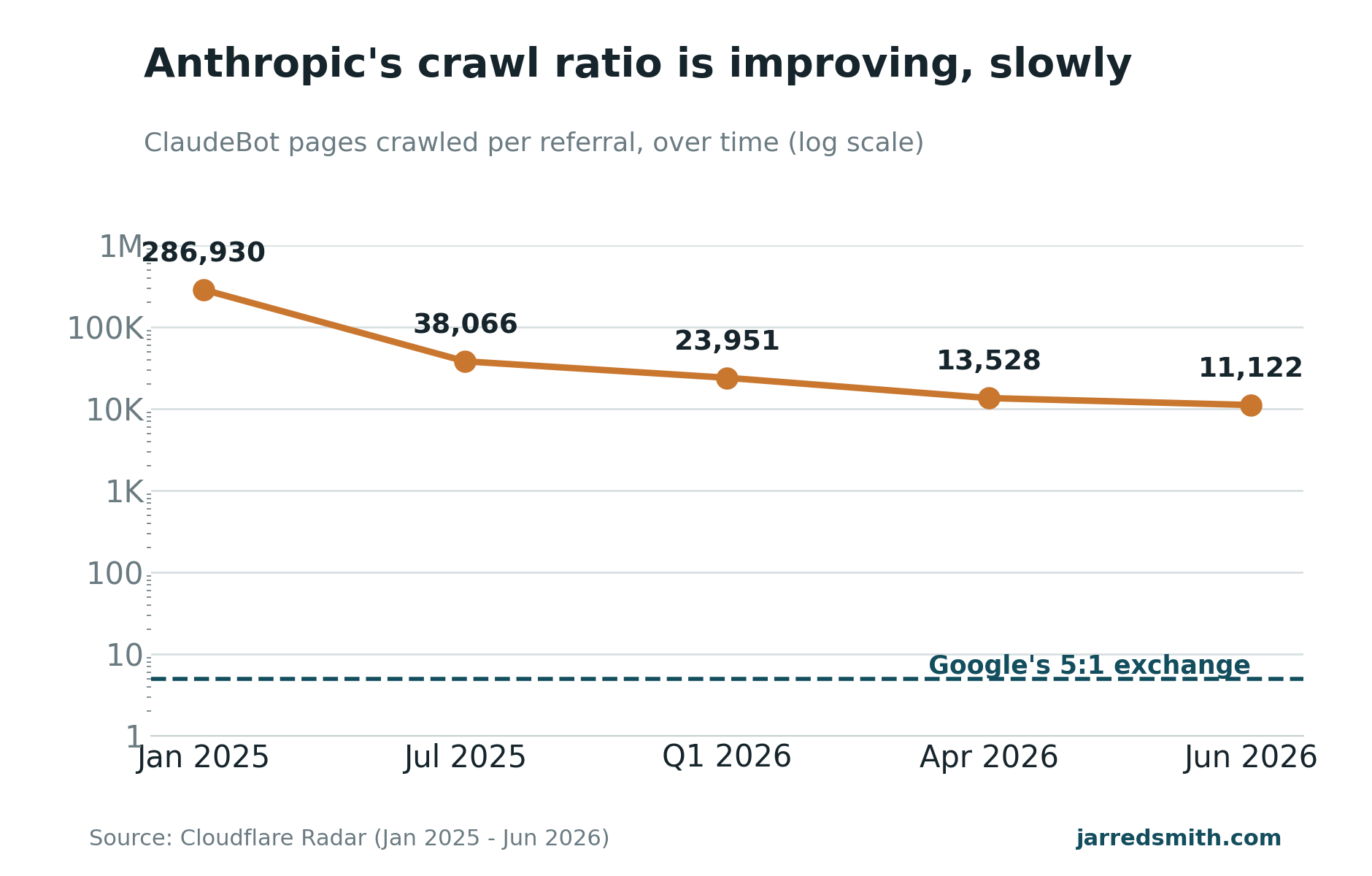
And put a quarterly reminder on the calendar to re-check the ratios, because they move. ClaudeBot sat at an absurd 286,930 to one in January 2025, dropped to 38,066 by that summer, and reached 11,122 this June (Cloudflare data, via Market Anarchy). The direction is toward a fairer trade, even if the level is still thousands of times worse than the deal Google built the web on. When a training-heavy operator crosses into the low hundreds, the math for letting it in changes, and you want to notice when it does.
The decision under the decision
This only looks like an IT setting. Underneath it's a question about what your content is for.
If your site is a destination, a place people land and read and maybe buy, then a crawl that sends nobody back reads as pure cost, and the block button is right there for a reason. A lot of marketing has stopped working that way, though. Your content is increasingly the raw material an AI reads before it decides whether to put you in front of a person, and when that's the job, being crawled by the bots that cite you is worth more than the visit you didn't get. I wrote a whole book on that second idea, and the block-allow-charge decision is where it stops being a thesis and turns into a checkbox you have to tick this quarter.
There are real freeloaders in this story, and the block advice names them correctly. The trouble is that the bots most brands reach to block first are usually the ones earning them citations.
Jarred Smith is the author of Explainable: Why AI Recommends Some Brands & Ignores Others, an Amazon bestseller on AEO, GEO, and SEO. He's a marketing leader with nearly 20 years of experience across healthcare, public media, retail, and environmental services. Find him at jarredsmith.com.