Is AEO Measurable? What the 2026 Research Shows About Tracking AI Citations
There's a take making the rounds on Reddit and LinkedIn that goes about like this. AEO is a con. You can't track citations from a language model, the output is probabilistic, the model won't tell you why it picked anyone, so no amount of optimization work can move your visibility. A lot of them have done SEO for fifteen+ years and they're watching a fresh acronym get sold to clients with the confidence of a timeshare pitch. I get the reflex and they aren't fools for thinking that way.
In my opinion, however, the argument has a hole in it wide enough to drive the entire field of statistics through.
The stakes here aren't trivial, which is why the fight is worth having. ChatGPT crossed 800 million to a billion weekly users early this year, double where it sat in February 2025. Google's AI Overviews now show up on close to half of all searches. The traffic these answers send is smaller than classic search but converts at a different level. One analysis of 312 technology firms put AI-referred conversion at 14.2% against 2.8% for Google organic. When the buyers worth having are increasingly asking a model who to trust, “can we influence that answer” stops being academic.
Where the skeptics are right
I’ll start with the part they've got correct. Language models are non-deterministic. That means that the same query, on a different day, and different wording in the answer, can sometimes have different sources entirely. Ahrefs found that AI Overview content changes around 70% of the time for the same query, and when it regenerates, close to half the citations get swapped out. A March 2026 paper from Ronald Sielinski at IQRush put hard numbers on the problem. Across Perplexity, SearchGPT, and Gemini, citation counts follow a power-law shape and bounce around enough that a lot of the apparent gaps between domains sit inside the noise floor of the measurement. He sampled at ten-minute intervals and watched the rankings reshuffle. His conclusion, which I agree with, is that a single-run measurement gives you a “misleadingly precise” picture. If your AEO dashboard is one query you ran once last week, the skeptics are describing you accurately. That reading is closer to a horoscope than a metric.
Measuring a system that won't hold still

The leap they make is the one that breaks. Going from “individual outputs vary” to “therefore nothing here is measurable” skips past the entire discipline built to handle variation. No pollster can tell you how one specific person will vote. They sample a few hundred and call a national race within a couple of points. Nobody can predict a single coin flip, and yet ten thousand flips produce a distribution so reliable it's boring. A probabilistic system is one you measure with a sample rather than a single look. That's the correction the research has been converging on. An April 2026 paper from Julius Schulte and co-authors carries the whole thesis in its title, “Don't Measure Once”. Their case is that you should treat a brand's AI visibility as a distribution across many runs instead of a single-point outcome. The monitoring tools built for this run the same prompts repeatedly, a method the vendors call multi-sampling, to establish a baseline that holds. Search Engine Land described the approach most serious teams land on, which is to define 250 to 500 high-intent queries as a population proxy, sample them across platforms over time, and read the aggregate the way you'd read a poll. Do that, and the noise that wrecks a single query averages into something stable.
The 1.2 million citation study
Then there's the third claim, that the models give you no insight into how they choose sources. Somebody forgot to tell Kevin Indig.
Across late 2025 and early 2026, Indig ran what's still the most rigorous public work on this. He analyzed 1.2 million ChatGPT responses, pulled out 18,012 verified citations, and used sentence-transformer embeddings and a Jaccard sliding-window match to find where on each cited page the model lifted its answer, down to the decile. That's definitely not just guesswork. He reconstructed citation behavior from the outside, at scale, with a method other people can run for themselves.
What he found held across randomized validation batches with a p-value of 0.0, which in plain English means the pattern isn't an accident. 44.2% of ChatGPT citations come from the first 30% of a page. He calls it the ski-ramp, heaviest at the top and dropping toward nothing by the bottom, where the final tenth of a page collects between 2.4% and 4.4% of citations. A follow-up study of about 98,000 citation rows across seven verticals found roughly 30 domains capturing 67% of citations in a given topic, and pages ranking first in Google getting cited by ChatGPT 43.2% of the time, about 3.5 times the rate of pages sitting past the top 20.
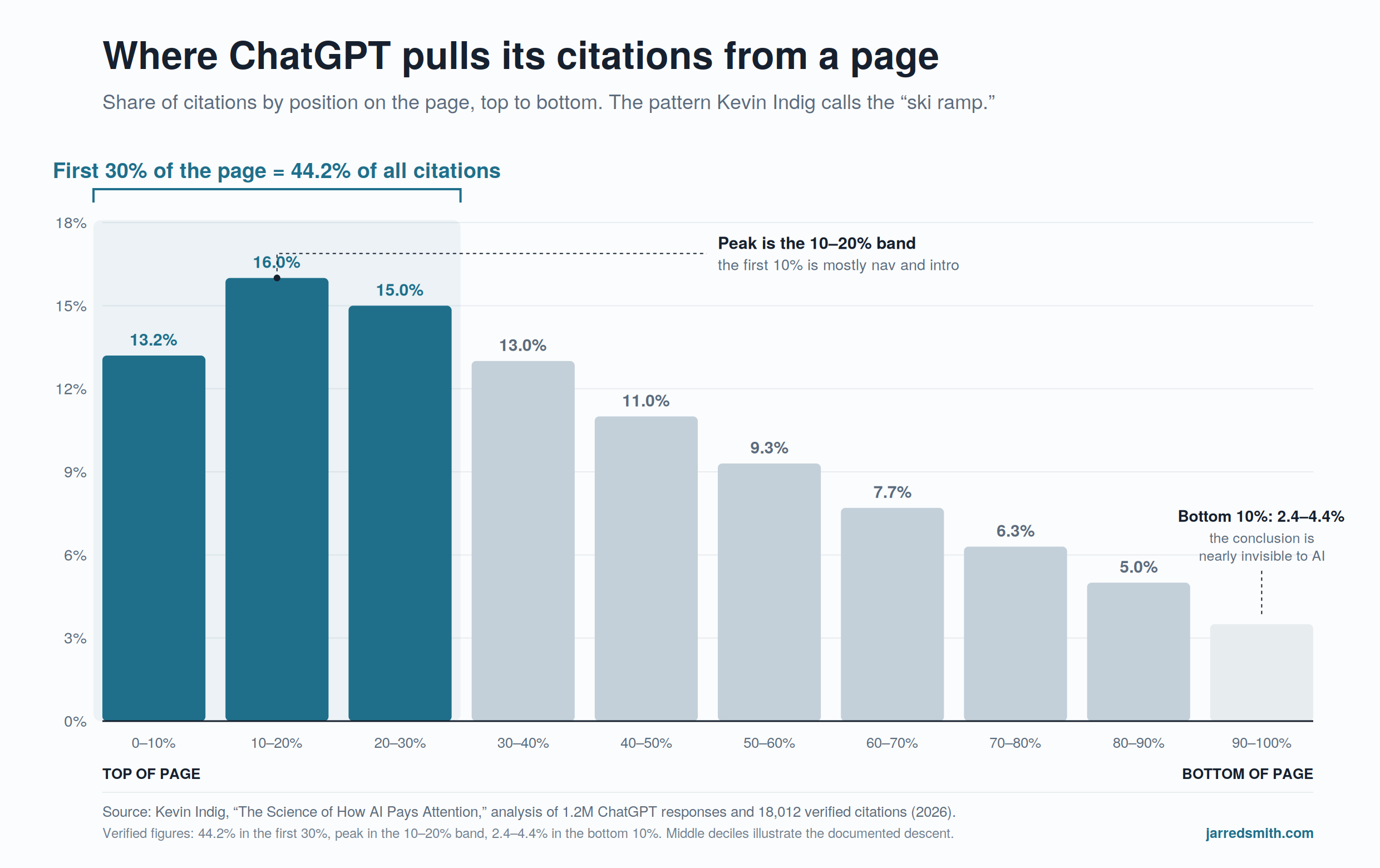
None of that survives if citations are pure noise. You can't find a stable, replicable, statistically significant pattern inside randomness. The pattern is there, it holds up under validation, and it points at specific, fixable things about how a page is built. That's the case for AEO sitting in a single study.
What correlates with getting cited
If this were all unknowable, the correlations wouldn't exist, but they do. Ahrefs studied 75,000 brands and found branded web mentions to be the single strongest predictor of turning up in Google AI Overviews, at a 0.664 correlation, with YouTube presence close behind across ChatGPT, AI Mode, and Overviews. The Princeton GEO study, the ACM KDD 2024 paper that named this whole field, ran controlled experiments and found that adding citations, statistics, and quotations to a page lifted its visibility in generative answers by up to 40%, with plain readability improvements adding another 15 to 30%. AirOps found that pushing the same content across many publications instead of only your own site raised AI citations by as much as 325%.
Argue about how durable any single one of those numbers is, fine; that's a fair fight. But the field is turning out numbers like these by the dozen, and that's the single thing “AEO can't be measured” needs to not be true.
If you're already doing the work
What do you do with this if you're putting in real effort? Stop running one query and calling it a reading. Build a fixed set of a few hundred buyer-intent prompts, run them on a schedule across ChatGPT, Perplexity, Gemini, and AI Overviews, and watch the trend rather than any single event. Mind where your answer sits on the page, because if 44% of citations come out of the top third, the useful part can't be buried under six paragraphs of warm-up. Spend at least as much energy getting mentioned off your own site as on it, since branded mentions and earned distribution showed up as stronger signals than one more post on your own domain. The step most people skip is the simplest one. Report your numbers as ranges with a direction, the way a pollster reports a margin of error, not as a lone confident percentage. Anyone who hands you one decimal point and no interval is making the same mistake the skeptics are annoyed about.
The skeptics are half right. Plenty of AEO gets sold on a single screenshot and a lot of nerve, and that totally deserves the eye-roll it gets. But there's a difference between criticizing how a thing is being measured and claiming it can't be measured, and the loudest voices online keep sliding from the first into the second without noticing the gap. The research keeps surfacing patterns that replicate and hold their significance.
I wrote a book about why AI surfaces some brands and ignores others, and the short version is that these models are more legible than people assume, as long as you quit staring at one answer and start reading the pattern behind a few hundred.
Jarred Smith is the author of Explainable: Why AI Recommends Some Brands & Ignores Others, an Amazon bestseller on AEO, GEO, and SEO. He's a marketing leader with nearly 20 years of experience across healthcare, public media, retail, and environmental services. Find him at jarredsmith.com.